1). 네이버 카페(루씬 한글분석기 오픈소스 프로젝트) 에서 arirang-morph-1.0.0.jar , arirang.lucene-analyzer-5.0-1.0.0.jar 를 다운받고 sole 웹 서버의 라이브러리 폴더에 복사한다. (~/solr-5.3.0/server/solr-webapp/webapp/WEB-INF/lib)
2). 생성한 core 폴더 /conf/managed-schema.xml 파일에 아래의 내용을 추가한다.
<!-- arirang -->
<fieldType name="text_ko" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.ClassicFilterFactory" />
<filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" />
<filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory" />
<filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory" />
<filter class="solr.StopFilterFactory" words="stopwords.txt"
ignoreCase="true" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.ClassicFilterFactory" />
<filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" />
<filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true" />
<filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory" />
<filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory" />
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true" />
</analyzer>
</fieldType>
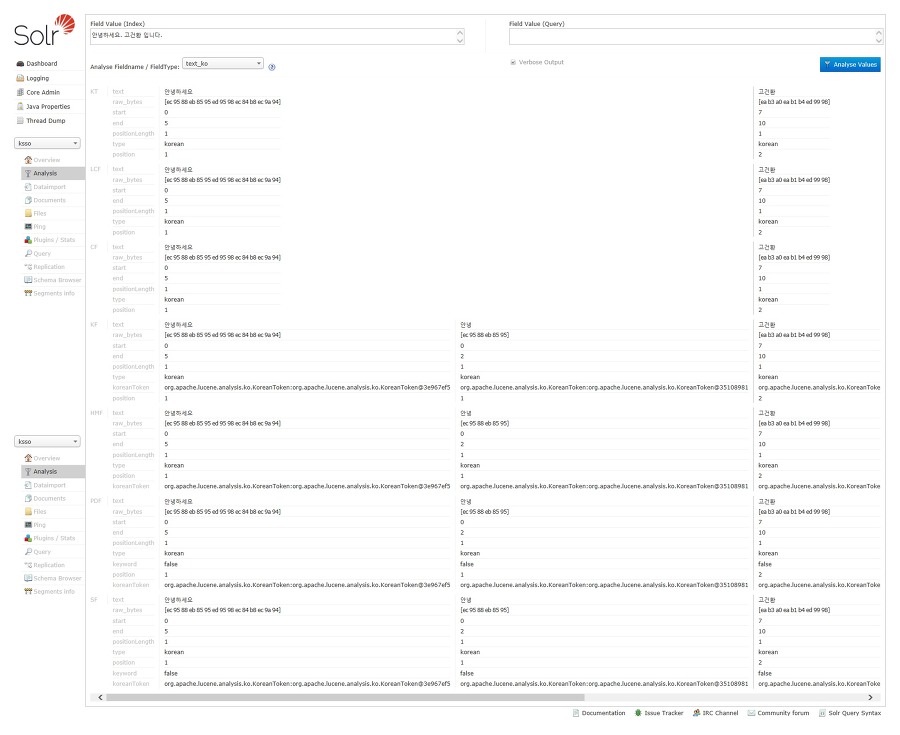
3). solr 데몬을 다시 재시작 하고 core 선택 후 analysis 기능을 이용하여 확인 가능하다.
명령어 예제: ./solr restart -s /home/kogun82/workspace/kobic -p 1818
출처 : https://kogun82.tistory.com/156
apache solr-5.3.0 한글 분석기 설치
1). 네이버 카페(루씬 한글분석기 오픈소스 프로젝트) 에서 arirang-morph-1.0.0.jar , arirang.lucene-analyzer-5.0-1.0.0.jar 를 다운받고 sole 웹 서버의 라이브러리 폴더에 복사한다. (~/solr-5.3.0/server/solr-webapp/webap
kogun82.tistory.com
'DB > Solr' 카테고리의 다른 글
| [Solr] 참고 자료 (0) | 2023.02.06 |
|---|---|
| [Solr] Solr 7.4.0 config set 관리하기 (0) | 2023.02.06 |
| [Solr] Solr 실행 시 오픈 파일 개수 설정하기 (0) | 2023.02.06 |
| [Solr] apache solr-5.3.0 데이터베이스 (MySQL) 연동 및 인덱스 작업 (0) | 2023.02.06 |
| [Solr] 검색엔진/Solrapache solr-5.3.0 설치 및 실행 (0) | 2023.02.06 |