엘라스틱서치 알아보기 프로젝트는 엘라스틱서치 실무가이드의 목차와 내용을 참조하였습니다. 이 포스트를 읽는 분들이라면 엘라스틱서치 실무가이드 책을 한권 반드시 구매하는 것을 권장합니다.
엘라스틱서치 주요 API 알아보기
구체적으로 어떠한 API가 있는지 알아보기 전에 먼저 어떤 종류의 API가 있는지부터 알아보겠습니다.
분류해보자면 대표적으로 아래 4가지 API가 존재합니다.
- 인덱스 관리 API(Indices API)
- 문서 관리 API(Document API)
- 문서의 추가/삭제/수정 등을 담당
- 검색 API(Search API)
- 집계 API(Aggregation API)
- 통계 등을 제공
모든 API는 HTTP 통신을 이용하여 RESTful하게 사용가능합니다.
인덱스 관리 API
인덱스 생성
인덱스를 생성할 때는 이전에 엘라스틱서치 구성요소에서 배웠던 매핑(Mapping)을 이용하여 문서에 포함된 필드 및 필드 타입 등을 설정 가능합니다.
단, 주의할 점은 일단 매핑 정보가 한번 생성되면, 변경이 불가능하다는 점입니다. 잘못 생성했거나 혹은 변경해야 할 경우에는 데이터를 삭제하고 재색인 과정을 거쳐야 합니다.
인덱스 생성은 아래와 같이 PUT 메소드를 이용하여 수행하시면 됩니다.

위의 인덱스 생성 매핑에 관련되어 알아두셔야 할 것은 위의 justString 필드의 필드 타입이 {"type": "keyword"}로 정의되어 있는 것이 보이실 겁니다. justString 필드의 이름처럼 keyword 타입은 그냥 문자열을 저장할 때 쓰입니다.
반면에, stringTobeAnalyzed 필드의 필드 타입은 {"type":"text"}로 정의된 것이 보일겁니다. 형태소 분석이 되어 검색되어야 할 필드는 text 필드 타입을 갖는 것이 바람직합니다. 또한 text 필드 타입을 갖는 필드가 있을 때, 뒤에 설명드리겠지만 분석기도 따로 설정하는 것이 가능합니다.
인덱스 삭제
인덱스 삭제는 아래의 그림과 같이 DELETE 메소드를 이용하여 수행하시면 됩니다. 인덱스 삭제는 취소가 불가능하니 삭제할 때 주의하셔야 합니다.

문서 관리 API
문서 관리 API는 다음과 같은 것들이 있습니다.
하나의 문서를 처리 Single Document API
- Index API : 하나의 문서 색인
- Get API : 하나의 문서 조회
- Delete API : 하나의 문서 삭제
- Update API : 하나의 문서 업데이트
다수의 문서를 처리 Multi Document API
- Multi Get API : 다수의 문서 조회
- Bulk API : 다수의 문서 색인
- Delete By Query API : 다수의 문서 삭제
- Update By Query API : 다수의 문서 업데이트
- Reindex API : 인덱스의 문서 재색인
문서 생성
문서 생성은 아래와 같은 방식으로 하면 됩니다. POST 메소드를 이용하고, /인덱스이름/_doc/문서id 순으로 입력하시면 됩니다. 뒤의 문서id 부분을 입력하지 않을 경우에는 UUID라는 것을 통해 무작위 값이 생성되는데, 무작위 값을 그대로 이용해도 되지만 별로 권장되는 행위는 아닙니다. 그 이유는 나중에 다른 데이터베이스와 연동 시에 규칙적이고 순서대로 배열된 id는 강력한 힘을 발휘할 수 있기 때문입니다.

문서 조회
문서 조회는 GET 메소드를 이용하시면 됩니다. /인덱스이름/_doc/문서id의 형식은 동일합니다.

아래 그림과 같이 /인덱스이름/_search 를 이용하면 전체 문서의 조회도 가능합니다.

문서 삭제
문서 삭제는 DELETE 메소드를 이용하여 동일하게 진행하면 됩니다.

검색 API
검색 API의 작동에는 두가지 방식이 존재합니다.
- URI 형태의 방식
- 기존에 사용하던 http://localhost:9200/index/_doc/1 과 같은 방식
- RESTful API 방식인 QueryDSL을 사용하여 Request Body에 내용을 추가하여 검색하는 방식
일반적으로 2번의 방식인 QueryDSL을 사용하는 방식이 더 선호됩니다. 다만, 아래 그림과 같이 두가지를 섞어서 검색 API를 사용할 수도 있습니다.
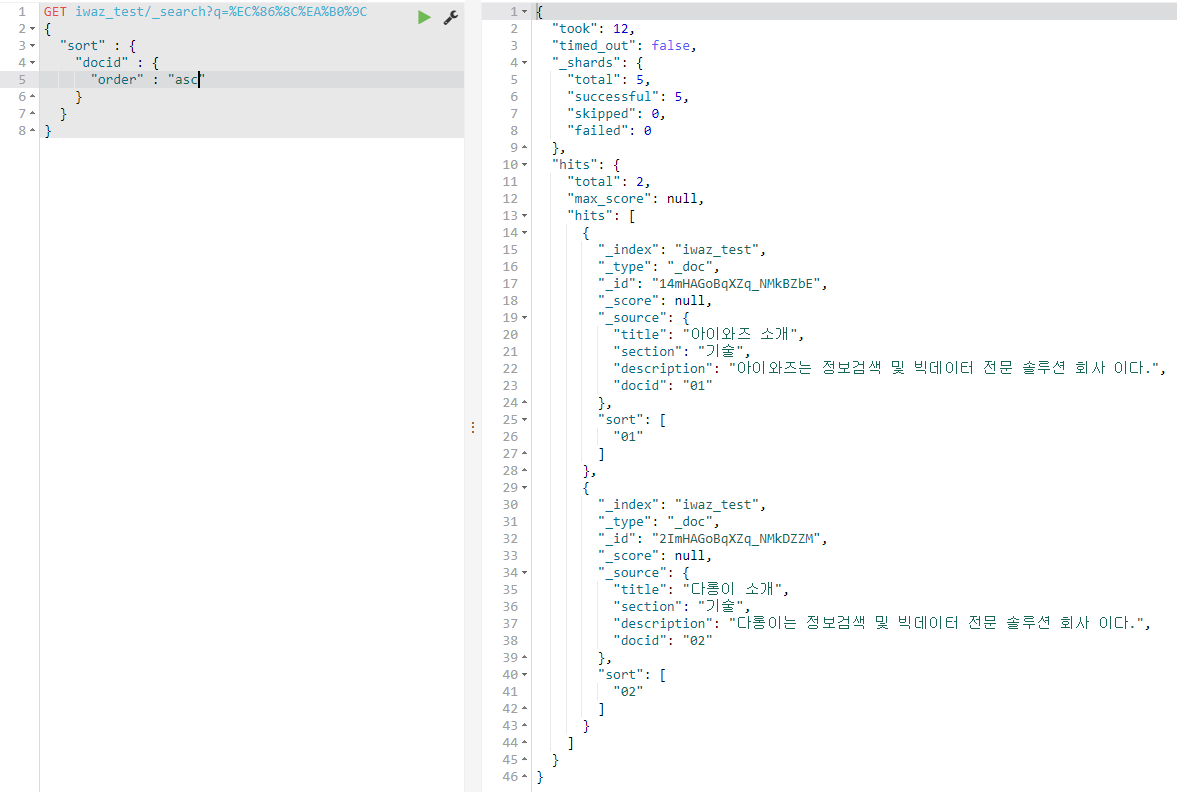
참고사항 1: q=뒤에 붙은 %EC%86%8C%EA%B0%9C는 '소개'라는 글자가 인코딩된 것입니다. 키바나에 그냥 한글 문자열로 '소개'를 파라미터로 넘겼을 때, 제대로 결과 값이 반환되지 않는 현상이 있습니다.
참고사항 2: q=뒤에 특정 필드를 검색하고 싶다면 q=필드명:검색내용 으로 검색하면 됩니다. 이를테면 q=section:기술 과 같은 형식으로 수행하시면 될 것입니다. 따로 필드명이 없는 경우에는 전체 필드를 대상으로 검색합니다.
QueryDSL은 가독성이 높고 다양한 표현을 하는 것을 도와줍니다. 조건을 중첩하여 어러 개 만들 수도 있고 집계 등 복잡한 쿼리도 작성할 수 있습니다. URI는 반면에 중첩된 형태는 표현이 불가능합니다.
검색 API 수행 시에는, 위의 결과 JSON에서처럼 여러가지 메타 데이터가 함께 표출됩니다. _shard에서는 성공적으로 반환한 샤드의 수와 실패한 샤드의 수를 알 수 있습니다. 성공과 실패의 여부는 시간 제한(time_out)에 따라 결정됩니다. 만일 실패한 샤드의 수가 높다면 time_out을 조금 더 늘려주면 될 것입니다. 다만, 서비스가 너무 느려지지 않게 주의해야 할 것입니다.
그리고 hits에서는 총 몇개의 문서가 검색조건에 부합했는지 알려줍니다. score는 검색 조건에 부합한 정도에 따라 부여됩니다.
QueryDSL 검색 API 입력 시에 옵션 정보
- size : 반환할 결과의 개수 (Default: 10)
- from : 몇 번째 부터 반환할지 ex) 스코어 3순위부터
- _source : 반환을 원하는 특정 필드가 있을 때 입력
- sort : 특정한 필드를 기준으로 정렬하고 싶을 때 입력
- query : 검색 조건 입력 match, term 등등..
- filter : 검색 결과 내에서 재검색하고 싶을 때 입력 (단, 이 경우 score 값은 사라짐)
집계 API
각종 통계 데이터를 실시간으로 제공합니다.
데이터 집계
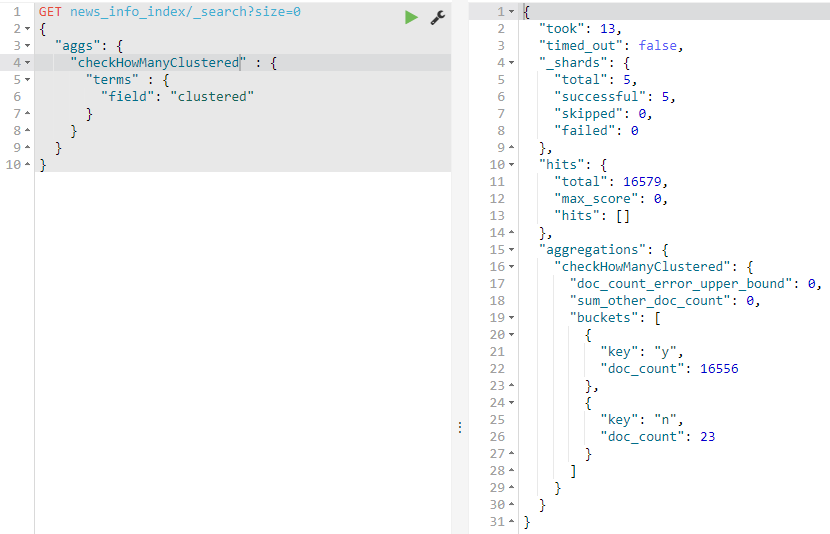
위의 그림은 집계 API 예제입니다. 예제에서 유의깊게 봐야 할 것은 다음과 같습니다.
- size=0를 명시하여 실제 데이터는 나오지 않게 하였습니다.
- aggs 라는 body 정보를 줍니다.
- checkHowManyClustered 는 사용자가 정의하는 Alias 같은 개념입니다.
- terms 의 내부에 field를 정의하고 field에 집계하고 싶은 필드를 입력하면 됩니다.
- buckets 이라는 배열 안에 집계 결과 데이터가 포함되어 있습니다.
- 사용자의 요구에 따라 버킷 안에 또 다른 버킷 결과를 추가할 수도 있습니다.
결과를 보면, clustered라는 필드에 'y'라는 데이터가 해당하는 경우가 16556개이고,
'n'이라는 데이터가 해당하는 경우는 23개인 것을 알 수 있습니다.
데이터 집계 타입
데이터 집계 타입은 다음과 같이 4가지가 존재합니다.
- 버킷 집계(Bucket Aggregation)
- 문서의 필드 기준으로 버킷을 집계합니다.
- 매트릭 집계(Metric Aggregation)
- 문서에서 추출된 값을 이용하여 합계, 최대값, 최소값, 평균값 등을 계산합니다.
- 매트릭스 집계(Matrix Aggregation)
- 행렬 값을 합하거나 곱합니다.
- 파이프라인 집계(Pipeline Aggregation)
- 일반적 파이프라인의 개념으로 집계에 의해 생성된 집계 결과를 이용해 또 다시 집계합니다.
[엘라스틱서치 알아보기 #4] 엘라스틱서치 주요 API 알아보기
엘라스틱서치 알아보기 프로젝트는 엘라스틱서치 실무가이드의 목차와 내용을 참조하였습니다. 이 포스트를 읽는 분들이라면 엘라스틱서치 실무가이드 책을 한권 반드시 구매하는 것을 권장
velog.io
좋은 글을 써주신 jakeseo_me 님 감사합니다
'DB > ElasticSearch' 카테고리의 다른 글
| [ElasticSearch]ElasticSearch Template (0) | 2023.02.06 |
|---|---|
| [ElasticSearch]Logstash jdbc 연결(MSSQL) (0) | 2023.02.06 |
| [엘라스틱서치 알아보기 #3] 엘라스틱서치 용어 및 개념 간단히 살펴보기 (0) | 2023.02.06 |
| [엘라스틱서치 알아보기 #2] DB만 있으면 되는데, 왜 굳이 검색엔진? (0) | 2023.02.06 |
| [엘라스틱서치 알아보기 #1] 엘라스틱서치는 검색엔진이다 (0) | 2023.02.06 |