하둡에 대해 알아보기 전에 큰 흐름에서의 하둡에 대해 이해를 해보자. 하둡은 기본적으로 빅데이터를 처리하는 과정 속에서 사용되어진다. 빅데이터를 처리하는 흐름으로는 우선 데이터를 수집한 후에, 저장하고 처리한다. 그 결과를 바탕으로 분석하고 결과를 표현하게 된다. 이러한 단계 중에 빅데이터를 어떻게 저장하고, 저장된 정보를 어떻게 잘 처리하는지에 대한 부분이 하둡이 담당하는 역할이라고 할 수 있다.
Hadoop (High-Availability Distributed Object-Oriented Platform)
자바 소프트웨어 프레임워크로 대량의 자료(빅데이터)의 분산 저장과 분석을 위한 분산 컴퓨팅 솔루션이다. 일반적으로 하둡파일시스템(HDFS)과 맵리듀스(MapReduce)프레임워크로 시작되었으나, 여러 데이터저장, 실행엔진, 프로그래밍 및 데이터처리 같은 하둡 생태계 전반을 포함하는 의미로 확장 발전 되었다. 한문장으로 정리하면, 데이터의 양이 너무 많으니 분산해서 저장한다는 의미이다.
전체적인 흐름을 익힌 후에 디테일한 개념을 적어보겠다.

하둡에서의 빅데이터
현재 우리는 데이터 홍수의 시대에 살고있다. 그리고 발생화는 데이터는 갈 수록 많아지고 있다. 빅데이터란 한대의 컴퓨터로는 저장하거나 연산하기 어려운 규모의 거대 데이터를 의미한다. 따라서 빅데이터 같은 경우는 여러대의 컴퓨터로 나눠서 일을 처리해야한다. 이를 분산이라고 한다. 그리고 이렇게 큰 데이터를 한번에 저장하기는 힘들다. 이러한 데이터를 알아서 여러대의 컴퓨터에 나눠서 저장해주고, 필요시 알아서 불러오는 시스템이 하둡이다. 같은 내용을 중복되게 저장을 하기 때문에 손실되더라도 복구가 가능하다. 이러한 하둡의 장점은 분석 시 나눠서 데이터를 분석하고 합치면 되므로 빠르다. 하지만 저장된 데이터를 변경하는 것이 불가능하고, 실시간 데이터와 같은 신속한 작업에서는 부적합하다.
정형데이터 뿐만 아니라 비정형데이터도 사용이 가능하기 때문에, 모든 분야에서도 활용가능하다고 할 수 있다.
하둡의 동작흐름
데이터가 들어오면, 데이터를 쪼갠다. 그리고 그 데이터를 분리해서 저장한다. 따라서 데이터를 쪼갠 후에 어느 데이터 노드에 저장이 되어 있는지를 기록해 놓는 부분(메타데이터)이 필요하다. 정리하면, 하둡에서 데이터를 저장하기 전에 네임노드에서 분산을 하고 저장위치를 분배한다. 그 후에 여러개 중에 지정된 데이터 노드에 저장을 한다고 간단히 이해하자.
1. 하둡 버전
> 하둡의 단점중 하나가 버전이 다양하다는 것이다. 버전이 다양한것이 왜 단점인지를 이해하기 위해서는 기본적으로 각각의 버전별 특징을 알아야 한다.
1.1 하둡 v1
2011년에 자바 프레임워크로 분산저장과 병렬처리를 목적으로 하둡 v1이 탄생하였다.
분산저장의 경우 네임노드(name node)와 데이터노드(data node)로 나누어 처리된다. 이때 네임노드는 블록정보를 가지고 있는 메타데이터와 데이터 노드를 관리한다. 데이터노드는 데이터를 블록단위로 저장하면서 블록단위 데이터를 복제하여 데이터 유실에 대비한다.
병렬처리는 잡트래커(JobTracker)와 태스크트래커(TaskTracker)가 담당한다. 잡트래커는 전체 진행상황을 관리하고 자원관리도 처리합니다. 테스크트래커는 실제 작업을 처리하는 일을 합니다. 이때 병렬처리의 작업단위는 슬롯으로 맵 슬롯과 리듀스 슬롯이 있습니다. 병렬처리를 통해 클러스트당 최대 4000개의 노드를 등록가능합니다.
1.2 하둡 v2
> 하둡 v1은 하둡의 탄생이었다면, v2는 v1을 보안 발전시킨 것이라 할 수 있다. 2012년에 정식 발표된 하둡 v2는 잡트래커의 병목현상을 제거하기 위하여 YARN 아키텍처가 등장한다. YARN 아키텍처는 앞의 문제를 해결하기 위해서 잡트래커의 기능을 분리한다.
- 자원관리 : 리소스 매니저, 노드 매니저 (클러스트당 만개 데이터 등록가능)
- 애플리케이션의 라이프 사이클 관리(작업 관리) : 어플리케이션 마스터 (클러스트당 만개 데이터 등록가능)
- 작업 처리 : 컨테이너
컨테이너는 YARN 아키텍처의 작업의 처리 단위이다.
작업이 들어오면 애플리케이션 마스터가 생성되고, 애플리케이션 마스터가 리소스 매니저에 자원을 요청하여 실제 작업을 담당하는 컨테이너를 할당받아 작업을 처리한다. 컨테이너는 작업이 요청되면 생성되고, 작업이 완료되면 종료되기 때문에 클러스터를 효율적으로 사용할 수 있다. YARN 아키텍처는 컨테이너를 할당 받아 동작하므로 Spark, HBase, Storm 등 다양한 컴포넌트를 실행할 수 있다.
하둡 v1의 작업 단위는 잡(job)이고, 하둡 v2의 작업 단위는 애플리케이션(application) 이다. YARN 아키텍처가 도입되면서 이름은 변경되었지만 동일하게 관리한다.
1.3 하둡 v3
2017년에 정식 발표된 하둡 v3은 v2를 업그레이드 한 형식이다.
- 에레이져 코딩 도입으로 기존의 블록 복제를 대체하는 방식으로 HDFS 사용량을 감소시켰다.
- YARN 타임라인 서비스를 도임하여 기존 타임라인 서비스 보다 많은 정보를 확인가능하다.
- JAVA8을 지원한다.
- 2개 이상의 네임노드를 지원하여 스탠바이노드를 여러개 지원가능해졌다.(원래 하나만 가능)
기본적인 하둡에 대해 정리했다면, 이제 본격적으로 세부사항을 정리를 시작해 보자.
2. HDFS(Hadoop Distributed FileSystem)
하둡 분산형 파일시스템(HDFS)는 하둡 네트워크에 연결된 기기에 데이터를 저장하는 분산형 파일시스템으로 실시간 처리보다는 배치처리를 목적으로 설계되었다. 따라서 작업량이 작거나 빠른 데이터 응답이 필요한 작업에서는 적합하지 않다.
2.1 HDFS의 4가지 특징
기본적으로 HDFS는 데이터를 블록 단위로 나누어 저장한다. 따라서 큰 데이터를 나누어 저장하므로 단일 디스크 보다 큰 파일도 저장이 가능하다. 블록단위가 256MB라면 1G파일은 4개의 블록으로 나누어 저장된다. 만약 블록단위보다 작은 크기의 파일이라면 파일을 나누지 않고 그데로 저장된다.
블록에 문제가 생겨 데이터가 손실되는 경우를 막기 위해 HDFS는 각 블록을 복제하여 중복 저장한다. 즉, 하나의 블록은 3개의 블록으로 복제되어 저장된다. 따라서 1G 데이터를 저장할 때 3G의 저장공간이 필요하다고 할 수 있다.
HDFS는 읽기 중심을 목적으로 만들어 졌기 때문에 파일의 수정은 지원하지 않는다. (읽는 속도를 높인다.)
맵리듀스(아래에서 나옴)는 HDFS의 데이터의 지역성을 이용해서 처리 속도를 증가시킨다. 데이터를 처리할 때 데이터를 알고리즘이 있는 곳으로 이동시켜 처리하지 않고, 데이터의 위치에서 알고리즘을 처리하여 데이터를 이동시키는 비용을 줄일 수 있다.
2.2 HDFS 구조(Architecture)
기본적으로 HDFS는 마스터 슬레이브 구조이다. 관련설명은 아래와 같다.
| 마스터/슬레이브(Master/slave)는 장치나 프로세스(마스터)가 하나 이상의 다른 장치나 프로세스(슬레이브)를 통제하고 통신 허브 역할을 하는 비대칭 통신 및 제어 모델을 의미한다 |
아래의 그림처럼 분산처리 시스템이기 때문에 MapReduce와 HDFS는 기본적으로 Master와 Slave의 관점으로 구분이 된다. 쉽게 말하면, 분산되어져 있는 것들을 관리할 master가 필요하다고 생각하면 좋을 것 같다. 즉, 일을 시킬 컴퓨터가 하나는 있어야한다.

한기철, K-ICT 빅데이터 교육교재 중 발췌
MapReduce는 일을 어떻게 나눠서 수행하는지를 Master에서 관리하고, HDFS는 저장 시 어떻게 분산 저장할 지를 Master에서 관리한다.
HDFS는 마스터 슬레이브 구조로 하나의 네임노드와 여러 개의 데이타노드로 구성된다. 네임노드는 메타데이터를 가지고 있고, 데이터는 블록 단위로 나누어 데이터노드에 저장된다. 데이터를 익고 쓰려면 사용자는 메타데이터를 가지고 있는 네임노드를 이용하면 된다. 네임노드, 데이터노드, 블록에 대해 하나씩 알아보도록 하자.
2.3. 네임노드(namenode)
네임노드는 분산 처리 시스템에서 Master를 담당하며, 메타데이터 관리와 데이터노드를 관리한다.
- 네임노드는 각 데이타노드에서 전달하는 메타데이터를 받은 후에 전체 노드의 메타데이터 정보와 파일 정보를 묶어서 관리한다.
- 파일 시스템을 유지하기 위해 메타데이터를 관리한다.
- 데이터를 저장할 시 기본적으로 블록단위로 들어오게 된다. 이때 들어온 블록들을 어느 데이타노드에서 저장 할 지를 정해준다고 이해하자.
데이터노드는 실제로 데이터를 저장하는 컴퓨터기 때문에 에러가 날 수도 있다. 따라서 네임도드와 데이터 노드는 3초마다 하트비트(heartbeat)를 주고 받는다. 쉽게말하면 데이터 노드에서 살아있다고 네임노드에 문서를 보내 알려주는 것이다. 이러한 알림을 3초마다 보내기 때문에, 알림이 안오면 문제가 생겼다고 판단한다. 이러한 문제가 생긴다면 다른 데이터 노드에 복제된 블럭을 가지고 와서 사용하면 된다.
2.3.1 메타데이터
메타데이터는 전체적인 구조를 나타낸다. 그리고 메타데이터는 파일이름, 파일크기, 파일생성시간, 파일접근권한, 파일 소유자 및 그룹 소유자, 파일이 위치한 블록의 정보 등으로 구성된다. 저장위치는 사용자가 설정한 위치(dfs.name.dir)에저장된다.
2.4. 데이타노드(datanode)
데이타노드는 데이터들이 저장되는 컴퓨터이다. 데이타노드는 파일을 저장하는 역할을 하며, 이떄 파일은 블록단위로 저장된다. 데이타노드는 주기적으로 네임노드에 하트비트와 블록리포트를 전달한다.
- 하트비트 : 데이타노드의 동작여부를 판단하는데 이용되고, 네임노드에서는 하트비트가 전달되지 않는 데이터노드는 동작하지 않는 것으로 판단하여 더이상 데이터를 저장하지 않도록 설정한다.
- 블록리포트 : 블록의 변경사항을 체크하고, 네임노드의 메타데이터를 갱신한다. 블록파일은 사용자가 설정한 위치(dfs.data.dir)에 저장된다.
2.4.1 데이타노드의 상태
데이타노드는 상태를 나타내는 정보로 활성상태와 운영상태를 확인할 수 있다.
활성상태
데이터노드가 Live, Dead 상태인지를 나타낸다. 데이터노드가 하트비트를 통해 활성 상태가 확인이 되면 Live 상태이다. 만약 문제가 발생하여 지정 시간동안 하트비트를 받지 못하면 네임노드는 데이터 노드의 상태를 Stale 상태로 변경하고, 그 이후에도 지정한 시간동안 응답이 없으면 Dead 노드로 변경한다.
운영상태
운영 상태는 보통 데이터 노드의 업그래이드나 작업을 하기 위해 서비스를 잠시 멈추어야 할 경우 블록을 안전하게 보관하기 위해 설정한다. 운영상태의 종류에는 아래와 같다.
| NORMAL | 서비스 상태 |
| DECOMMISSIONED | 서비스 중단 상태 |
| DECOMMISSION_INPROGRESS | 서비스 중단 상태로 진행 중 |
| IN_MAINTENANCE | 정비 상태 |
| ENTERING_MAINTENANCE | 정비 상태로 진행 중 |
2.5. 네임노드 구동 과정
기본적으로 네임노드는 Fsimage와 Edits를 읽어서 작업을 처리한다.
먼저 Fsimage를 읽어서 메모리에 적재한 후에 Edits 파일을 읽어와서 변경내역을 반영한다. 현재의 메모리 상태를 반영하여 Fsimage 파일을 생성한다. 데이터 노드로부터 블록리포트를 수신하여 매핑정보를 생성하고 서비스를 시작한다.
2.6 HDFS 파일 사용
HDFS의 파일에 대한 내용을 위에서 배웠다. 그렇다면, 내부의 파일을 사용하는 법에 대해 알아보자.
HDFS File Read

http://www.corejavaguru.com/bigdata/hadoop/hdfs-file-read
HDFS의 파일을 읽는 순서는 아래와 같다.
- open() 명령어를 통해 DistributedFileSystem에 있는 FileSystem의 파일을 연다
- PRC()를 NameNode를 호출하여 저장되어있는 블록이 저장된 DataNode의 주소를 받는다.
- DistributedFileSystem은 client가 데이터를 검색할 수 있도록 검색을 지원하는 입력 스트림인 FSDataInputStream를 client에게 준다. 그러면 그것을 통해 찾고자 하는 datanode와 DFSInputStream이 맵핑된다. 그리고 검색후 read() 명령어를 통해 호출을한다.
- datanode 주소가 저장된 DFSInputStream은 datanode와 연결되고, 데이터는 datanode에서 클라이언트로 가게된다. 이러한 형식으로 반복 read()가 호출하여 파일을 읽는다.
- 블록 끝에 도달하면 DFSInputStream은 데이터 노드에 대한 열결을 닫고, 다음 블록에 가장 접합한 데이터 노드를 찾는다.
- 읽기가 마치면 FSDataInputStram에서 close()를 호출한다.
PRC : remote procedure call, 은 별도의 원격 제어를 위한 코딩 없이
다른 주소공간에서 함수나 프로시저를 실행할 수 있게하는 프로세스 간 통신 기술
2.7 블록
Hadoop의 HDFS는 파일을 데이터 블록이라고 하는 작은 크기의 블록으로 나눈다. HDFS는 지정한 크기의 블록으로 나누어 지고 각각 독립적으로 저장된다. 지정한 크기보다 작은 파일은 실제 파일 크기의 블록으로 저장되고, 지정 크기보다 크다면 나눠서 저장된다. 따라서 파일의 모든 블록은 마지막 블록을 제외하고는 동일한 크기이다.
HDFS 데이터 블록은 기본적으로 검색 및 네트워크 트래픽 비용을 줄여준다. 기본적으로는 128MB의 크기의 덩이리이며, 크기는 재설정 가능하다.
2.8 HDFS Federation
HDFS Federation은 디렉토리 단위로 네임노드를 등록하여 사용하는 것으로, 파일이 많아짐에 따른 메모리 관리 문제를 해결하기 위해 하둡 v2 부터 지원됐다. 예를 들어 user, hadoop, tmp 세개의 디렉토리가 존재할 때, /user, /hadoop, /tmp 디렉토리 단위로 총 3개의 네임노드를 실행하여 파일을 관리하게 한다. 각각 독립적으로 관리하기 때문에 하나의 문제가 발생하더라도, 다른 네임노드에 영향을 주지 않는다.
2.9 HDFS High Availability(고가용성)
네임노드에 문제가 발생하면 모든 작업이 중지되고, 파일을 읽거나 쓸수 없게 된다. 하둡 v2에서 이 문제를 해결하기 위해서 HDFS High Availability을 제공한다. HDFS 고가용성(Hight Availability)은 이중화된 두대의 서버인 액티브(active) 네임노드와 스탠바이(standby) 네임노드를 이용하여 지원한다. 액티브 네임노드와 스탠바이 네임노드는 데이터 노드로부터 블록 리포트와 하트비트를 모두 받아서 동일한 메타데이터를 유지하고, 공유 스토리지를 이용하여 에디트파일을 공유한다.
- 액티브 네임노드는 네임노드의 역활을 수행한다.
- 스탠바이 네임노드는 액티브 네임노드와 동일한 메타데이터 정보를 유지하다가, 액티브 네임노드에 문제가 발생하면 스탠바이 네임노드가 액티브 네임노드로 동작한다.
액티브 네임노드에 문제가 발생하는 것을 자동으로 확인하는 것이 어렵기 때문에 보통 주키퍼를 이용하여 장애 발생시 자동으로 스탠바이 네임노드로 변경될 수 있도록 한다. 스탠바이 네임노드는 세컨더리 네임노드의 역할을 동일하게 수행하기 때문에, HDFS를 고가용성 모드로 설정하였을 때는 세컨더리 네임노드를 실행하지 않아도 됩니다. 고가용성 모드에서 세컨더리 네임노드를 실행하면 오류가 발생한다.
| 주키퍼(Zookeeper) Zookeeper(사육사)는 이름에서 그 역할을 쉽게 짐작할 수 있다. 분산 시스템 간의 정보 공유 및 상태 체크, 동기화를 처리하는 프레임워크로 이러한 시스템을 코디네이션 서비스 시스템이라고 한다. Zookeeper를 많이 사용하는 이유는 기능에 비해 시스템이 단순하기 때문이다. 분산 큐, 분산 락, 피어 그룹 대표 산출 등 다양한 기능을 가진다. 몇 개의 기본 기능만으로도 사용이 가능하다. |
2.10 HDFS safemode
safemode는 일기 전용 상태로 데이터 노드 수정이 불가능해서, 데이터의 추가, 수정, 복제가 일어나지 않는다. 보통 safemode는 노드에 문제가 생겼거나 서버 운영 정비를 위해 설정을 한다.
# 세이프 모드 상태 확인
$ hdfs dfsadmin -safemode get
Safe mode is OFF
# 세이프 모드 진입
$ hdfs dfsadmin -safemode enter
Safe mode is ON
# 세이프 모드 해제
$ hdfs dfsadmin -safemode leave
Safe mode is OFF
2.11 HDFS 휴지통
휴지통 기능이 설정되면 HDFS에서 삭제한 파일은 바로 삭제되지 않고, 각 사용자의 홈디렉토리 아래 휴지통 디렉토리(/user/유저명/.Trash)로 이동된다.
# 휴지통을 비움.
$ hadoop fs -expunge
# 휴지통을 이용하지 않고 삭제
$ hadoop fs -rm -skipTrash /user/data/file
3. 맵리듀스(Map Reduce)
맵리듀스의 기원은 구글에서 만든 Map Reduce라는 알고리즘에서 탄생됐다. 즉, Goggle MapReduce를 참고해서 Hadoop MapReduce 프레임워크를 만든것이다. 정리하면, 하둡은 분산처리가 가능한 시스템과 분산되어 저장된 데이터를 병렬로 처리가능하게 하는 맵리듀스 프레임워크의 결합한 단어라 할 수 있다. 즉, 하둡 분산 파일 시스템(HDFS)은 대용량 파일을 지리적으로 분산되어 있는 수많은 서버에 저장하는 솔루션이며, 맵-리듀스는 분산되어 저장된 대용량 데이터를 병렬로 처리하는 솔루션이다.
맵리듀스는 대용량 데이터 처리를 위한 분산 프로그래밍 모델이다. 분산되어 있는 데이터를 분석하려고 한다. 이때 분산된 데이터를 굳이 한 곳으로 모아서 분석을 한다면, 굉장히 오래걸리고 비효율적일 것이다. 따라서 특정 데이터를 가지고 있는 데이터 노드만 분석을 하고 결과만 받는 것이 맵리듀스이다. 통합분석이 아닌, 개별분석 후 결과를 취합한다고 생각하자.
예를 들어보면, 100개의 자료를 한 명이 보는 것 보다 100명이 하나씩 보는 것이 훨씬 빠르다. 이것이 분산처리의 핵심인데, 만약 여기서 하나의 자료의 크기가 다르거나, 정확한 일의 배분이 힘들 경우를 해결해 주는 역할이 맵리듀스의 역할이라고 할 수 있다.
맵리듀스는 Map단계와 Reduce단계로 이루어진다.
MAP단계
- Map은 분산되어있는 컴퓨터에서 처리하는 것이다.
- Map단계에서는 흩어져 있는 데이터를 key, value로 데이터를 묶어준다.
- key는 몇 번째 데이터인지, value는 값을 추출한 정보를 가진다. 예들들면, '빅데이터'가 key라면 value는 빅데이터라는 키가 몇번 나오는지 숫자가 적혀있는 것이다. 이러한 방식으로 분산되어 있는 컴퓨터에서 각각 key와 value를 구하게 된다. 구한 후에 통합하기 위해 통합하는 곳(Reduce)으로 보내주게 된다.
- 정리하면, Map은 흩어져 있는 데이터를 Key, Value의 형태의 연관성 있는 데이터 분류로 묶는 작업이다.
Reduce단계
- 최종적인 통합관리를 위해 Reduce를 해주는 것이다.
- 만약 A컴퓨터에서 빅데이터가 5번나오고 B컴퓨터에서 빅데이터가 10번 나왔다면, Reduce는 빅데이터가 총 15번 나왔다고 통합을 해주는 것이다. 통합이라는 자체가 줄여주는 의미가 있기 때문에 Reduce라고 쓰이는 것이다.
- Reduce단계는 Map단계의 key를 중심으로 필터링 및 정렬한다. 하둡에서는 이 Map과 Reduce를 함수를 통해서 구현하고 맵리듀스 잡을 통해 제어한다.
- 정리하면 Reduce는 Filtering과 Sorting을 거쳐 데이터를 추출, Map 작업 중 중복데이터를 제거하고 원하는 데이터를 추출하는 작업이다.
버전에 따른 MapReduce 차이
하둡 에코 시스템 1.0의 문제점은 관계형 데이터베이스 분석 시스템에 익숙한 많은 분석가들과 사용자들을 하둡으로 끌어들이는데 실패하는 원인이 되었으며, 이러한 문제점를 해결하기 위해서 하둡 에코 시스템 2.0에서는 맵-리듀스(Map-Reduce)를 버리고 YARN(Yet Another Resource Negotiator)을 채택하여 확장성과 데이터 처리 속도를 개선시켰다.

버전의 차이를 보면 위와 같다. 버전1에서는 MapReduce가 cluster resource management와 data processing을 처리하지만, 버전 2에서는 MapReduce가 data processing만을 처리하는 것을 볼 수 있다.
하둡 에코시스템
우리는 위에서 여러 프레임워크를 알아보았다. 하둡에서 데이터를 분석 유지 저장 관리 할 때 필요한 모든 것들을 에코시스템이라 한다. 즉, 하둡은 효율적인 데이터 처리와 분석을 위해 맵리듀스, 분산형 파일시스템(HDFS) 말고도 많은 구성요소로 포함된다. 구성요소들에 대해 알아보도록 하자.
하둡 코어 프로젝트 : HDFS(분산데이터 저장), MapReduce(분산처리)
하둡 서브 프로젝트 : 하둡 코어 프로젝트를 제외한 나머지 프로젝트로 데이터 마이닝, 수집, 분석 등을 수행한다.
하둡 서브 프로젝트 (분산데이터를 다루기 위해 만들어진 추가 project)
지금부터는 기존의 데이터가 아닌 분산 데이터이기 때문에 새롭게 생긴 용어들이다. 사실상 기존의 데이터를 다루는 데 사용되어지는 개념이지만, 분산되어 저장된 데이터를 처리하는 방식에 대한 이름을 붙인 것이라고 할 수 있다.
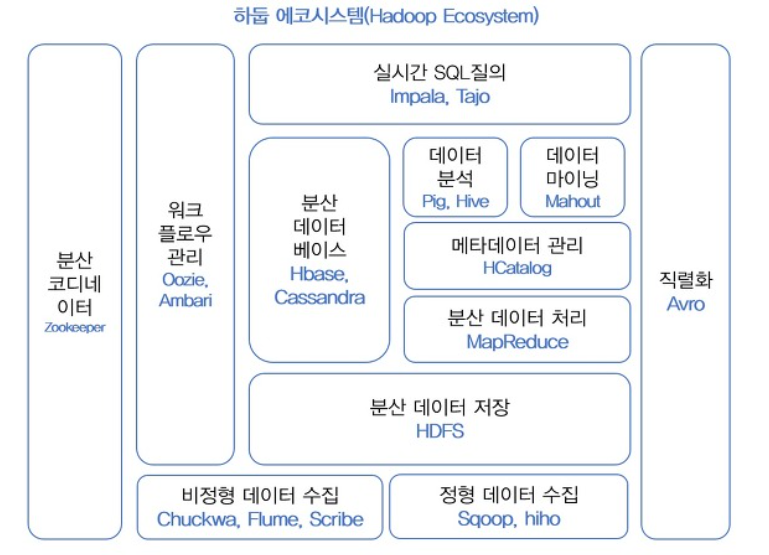
하둡 프로그래밍(위키북스)
하둡의 기능을 보안하는 서브 오픈소스 소프트웨어를 하나씩 알아보기 전에 주요 기술별로 역할을 아래의 표를 통해 확인을 한번 하고 내려가자.
| 구분 | 주요기술 |
| 빅데이터 수집 | 플럼(Flume) |
| 스쿱(Sqoop) | |
| 빅데이터 저장, 활용 | Hbase |
| 빅데이터 처리 | 하이브(Hive) |
| 피그(Pig) | |
| 마후트(Mahout) | |
| 빅데이터 관리 | 우지(Oozie) |
| H카탈로그(HCatalog) | |
| 주키퍼(Zookeeper) |
작업 흐름도
HDFS(하둡 저장 시스템) => MapReduce(데이터를 key value로 변경) => Hbase(변경된 데이터를 데이터베이스로 저장) => Pig, Hive, Mahout, Oozie(데이터를 분석해주는 툴)
하둡 에코시스템 버전
하둡 에코시스템은 각각 다른 프로그램들이 결합한 것이다. 따라서 각각 버전 업그레이트 되는 것이 다르다. 따라서 호환이 잘 맞지가 않는다. 따라서 통합관리가 필요하다. 우리는 따라서 통합관리가 되어 있는 배포판을 사용해야한다.
0. 하둡 사용자 인터페이스(Hue, Zeppelin)
하둡 휴(Hue, Hadoop User Experience)는 하둡과 하둡 에코시스템의 지원을 위한 웹 인터페이스를 제공하는 오픈 소스 이다. Hive 쿼리를 실행하는 인터페이스를 제공하고, 시각화를 위한 도구를 제공한다. 잡의 스케줄링을 위한 인터페이스와 잡, HDFS, 등 하둡을 모니터링하기 위한 인터페이스도 제공한다.
Zeppelin은 한국의 NFLab이라는 회사에서 개발하여 Apache top level 프로젝트로 최근 승인 받은 오픈소스 솔루션으로, Notebook 이라고 하는 웹 기반 Workspace에 Spark, Tajo, Hive, ElasticSearch 등 다양한 솔루션의 API, Query 등을 실행하고 결과를 웹에 나타내는 솔루션입니다.
+ Flamingo framework
1. Hbase
하둡에서 사용하는 데이터베이스는 관계형 데이터베이스가 아닌 NoSQL(비정형화된 데이터베이스) 이다. Hbase는 자바 언어로 만들어졌으며, HDFS를 이용하여 분산된 컴퓨터에 데이터를 저장한다. 그리고 Hbase는 압축 기능과 자주 사용되는 데이터를 미리 메모리에 캐싱하는 인-메모리(In-Memory)기술을 사용하여 데이터 검색 속도를 높인다.
HDFS와 Hbase가 헷갈릴 수 있다. HDFS가 원초적인 데이터를 분산저장 하는 곳이라고 생각하면되고, Hbase는 그 원초적 데이터를 가져와서 key, value 형태와 같이 가공을 해서 쉽게 가져다 쓸 수 있게 만든 데이터베이스라고 생각하면 된다.
NoSQL(Not Only SQL)은 대용량 데이터를 처리하기 위해서 탄생된 데이터베이스이다. 대용량 데이터를 저장하고 처리하기 위해서는 지리적으로 분산되어 있는 노드들에 대한 안정적인 관리가 필요하며, 속도보다는 데이터를 손실하지 않고 저장하는 방법과 더 많은 데이터를 처리하기 위해서 노드들을 쉽게 확장할 수 있는 방법에 중점을 두고 설계가 되었다고 보면 된다.
NoSQL의 큰 종류에 대해 알아보자. 'Key-Value store' 제품군으로는 멤캐시드(Mem-Cached)와 레디스(Redis, Remote Dictionary Server)등이 있으며, 키-밸류 형태로 이루어진 비교적 단순한 데이터 타입을 데이터베이스에 저장한다. 'Graph Database' 제품에는 네오포제이(Neo4j)가 있으며, 그래프 모델에서 필요한 정점(Vertex)와 간선(Edge) 그리고 속성(Property)등과 같은 정보를 데이터베이스에 저장하고, 'Document Store' 제품군에는 카우치DB와 몽고DB가 있으며, 문서 형태의 정보를 JSON 형식으로 데이터베이스에 저장한다. 마지막으로 'Wide Colum Store' 제품군에는 H베이스(HBase)와 카산드라(Cassandra)가 있으며, 컬럼안에 여러 정보들을 JSON 형태로 저장할 수 있다.
하둡 진영에서는 관계형 데이터베이스에 호감을 가지고 있는 분석가와 사용자들의 마음을 돌리기 위해서, 빠른 속도와 손 쉬운 사용 그리고 관계형 데이터베이스에서 사용하던 도구들을 이용할 수 있는 시스템을 만들기 위해서 노력하고 있다. 이러한 데이터베이스 제품들을 'NewSQL'이라고 부르고 있으며, 여기에는 그루터(Gruter)의 타조(Tajo), 구글의 드레멜(Dremel), 호튼웍스의 스팅어(Stinger), 클라우데라의 임팔라(Impala)등이 있다. 관련 내용은 아래의 Hive에서 다시 나오니 참고하자.
2. 주키퍼(Zookeeper)
Zookeeper(사육사)는 이름에서 그 역할을 쉽게 짐작할 수 있다. 분산 시스템 간의 정보 공유 및 상태 체크, 동기화를 처리하는 프레임워크로 이러한 시스템을 코디네이션 서비스 시스템이라고 한다. Zookeeper를 많이 사용하는 이유는 기능에 비해 시스템이 단순하기 때문이다. 분산 큐, 분산 락, 피어 그룹 대표 산출 등 다양한 기능을 가진다. 쉽게 설명하면, 리소스와 하둡의 구성요소 간의 불일치 문제를 중간에서 해결하는 역할이다.
3. Pig와 Hive Project
맵리듀스을 구현을 하려면 여러 언어들을 사용해야한다. 기본적으로 하둡은 자바로 개발되어 있기 때문에, 가장 많이 활용되는 언어는 자바이다.(다른 언어도 지원을 한다.) 따라서 초창기는 MapReduce를 자바를 통해서 직접 코딩을 했다. 그러나 자바코드는 굉장히 길기 때문에 자동으로 자바가 작동할수 있도록 스크립트 언어를 만들었는데, 그것이 Pig와 Hive이다.
- Pig : [Yahoo] 많은 사람들이 사용할 수 있도록 MapReduce 프로그램을 만들어 주는 고수준 언어를 만들겠다는 목적으로 만들어짐
- HIVE : [Facebook] SQL(유사) 구문에서 MapReduce를 자동생성하겠다는 목적으로 만들어짐
정리하면, Pig와 HIVE의 탄생으로 어려운 자바을 통해 MapReduce를 할 필요없어진 것이다.
3.1 Pig Project
맵리듀스 어플리케이션으로 개발해서 처리할 수도 있지만, 맵리듀스를 사용하지 않고 Pig를 사용해서도 분산파일 시스템에 저장된 데이터를 처리할 수 있게 만든 스크립트 언어이다. Pig는 Yahoo에서 개발되어 졌으며, Pig Latin language는 SQL과 유사한언어를 기본으로한 쿼리이다. pig는 명령 실행 작업을 수행한 후에 백그라운드에서 MapReduce의 모든 활동을 처리한다. 처리 후엔 결과물를 HDFS에 저장한다.
3.2 Hive Project
하둡은 하이브(Hive)가 없었던 시절인 하둡 v1에서는 맵-리듀스(Map-Reduce) 언어를 사용하여 하둡 분산 파일 시스템(HDFS)에 저장된 정보들을 조회(Query) 했다. 그러나 프로그램을 모르는 일반 사용자들이 맵-리듀스 언어를 사용하여 조회(Query)하는 일이 어려울 수 밖에 없었다. 이러한 문제점을 해결하기 위한 하이브는 하이브큐엘(HiveQL)이라는SQL과 거의 유사한 언어를 사용하여 일반 사용자들이 쉽게 데이터를 조회(Query)할 수 있도록 지원한다.
데이터를 다루는데는 관계형데이터베이스인 SQL이 일반적으로 가장 많이 사용된다. 따라서 분산파일로 저장된 데이터를 SQL로 다루기 위해 탄생한 것이 Hive이다. 최근에는 Hive를 활용하여 분산파일을 핸들링하는 것이 가장 일반적인 방법이다. 그러나 정형데이터의 경우만 SQL로 처리하는 것이 가능하고 반정형 데이터나 비정형 데이터는 SQL로 처리하기가 쉽지가 않다. 이런경우는 맵리듀스로 다시 프로그래밍을 해야할 필요가 있다. 정리하면 Hive는 SQL로 분산데이터 처리를 하기위한 것이다.
SQL 방법론 및 인터페이스의 도움으로 HIVE는 대용량 데이터 세트를 읽고 쓴기가 가능해진다. 쿼리 언어는 HQL (Hive Query Language)라고 불리며 실시간 처리와 일괄 처리를 모두 허용하므로 확장 성이 뛰어나고 모든 SQL 데이터 유형이 Hive에서 지원되므로 쿼리 처리가 더 쉬워진다.
하지만 하이브에도 몇가지 단점이 있다. 하이브큐엘(HiveQL)을 통해서 조회(Query)를 실행하면 내부적으로 맵-리듀스 언어로 변환하는 작업을 거치기 때문에, 맵-리듀스는 맵과 리듀스간의 셔플링 작업으로 인하여 속도가 느리다는 단점이 있다. 하이브큐엘(HiveQL)이 일반 사용자들에게 손쉽게 조회(Query)할 수 있는 방법을 제공하고 있지만 처리 속도가 느리다는 문제점은 여전히 가지고 있고, 하이브큐엘(HiveQL) 언어는 SQL과 비슷한 언어이지만 표준 SQL(Ansi SQL)의 규칙을 준수하지 않으며, 사용자들은 이러한 차이점을 다시 배워야하는 문제점을 가지고 있다.
하이브가 가지고 있는 문제점을 개선하기 위한 하둡 진영은 크게 두 갈래로 나뉘게 된다. "하이브를 완전히 대체하는 새 기술을 쓸 것인가?" 아니면 "하이브를 개선해 속도를 높일 것인가?" 이다. 하이브를 살려야 한다는 입장을 가장 강력하게 내세운 회사는 호튼웍스이다. 호튼웍스는 하이브를 최적화하고 파일 포맷 작업을 통해 하이브 쿼리 속도를 100배 끌어올리겠다는 비젼을 내 놓았습니다. 이것이 바로 스팅어(Stinger)이다. 하이브를 버리고 새로운 엔진을 찾아야 한다는 진영은 그루터의 타조와 클라우데라의 임팔라가 있다. 타조는 하이브를 개선하는데 한계가 명확하기 때문에 대용량 SQL 쿼리 분석에 적합하지 않다는 입장이며, 기획 단계부터 하이브를 대체하는 새로운 엔진을 개발하고 있다. 클라우데라의 임팔라는 좀 특이한 경우인데, 일정 규모 이상의 데이터는 임팔라로 분석이 불가능하다. 임팔라는 메모리 기반 처리 엔진이어서, 일정 용량 이상에서는 디스크 환경의 하이브를 사용해야 한다. 하지만 전체 틀에서는 하이브를 버리는 쪽으로 무게를 두고 있다고 이해하면 된다.
4. Mahout(마하웃)
복잡한 머신러닝이나 인공지능 알고리즘을 큰 데이터를 가지고 처리하려면, 별도의 알고리즘이 구현되어 있는 구현체가 필요하다. 즉, 머신러닝 알고리즘을 분산데이터에서 처리할 수 있도록 만드는 아웃풋 구현체라고 할 수 있다.
5. Sqoop
관계형데이터베이스(ex_마리아DB, 오라클, MySQL)와 하둡 간 데이터를 주고받는 것을 쉽게 할 수있는 프레임워크이다. 보통 Sqoop은 정형화된 데이터를 수집하는 기술로 많이 쓰인다. 만약, 소셜 네트워크 서비스에서 만들어지는 비정형 데이터의 경우는 클라우데라(Cloudera)의 플룸(Flume)과 아파치(Apache) 척화(Chukwa)등이나, 페이스북에서 사용하는 스크라이브(Scribe)를 비정형데이터 수집 기술로 쓰인다..
6. HCatalog
하둡에 저장된 데이터를 다루는 엔진이다. 사용자 마다 자신이 편한 Hive나 Pig 등 다른 명령어를 사용한다. 이럴 때 기본적인 메타나 스키마를 통일되게 공유하는 경우가 필요하다. 즉, HCatalog는 하나의 카탈로그로 관리를 하겠다는 의미이다.
7. Mrunit (엠알유닛)
맵리듀스를 테스트 하는 프레임워크이다.
8. Oozie(우지)
데이터를 시 용도에 맞게 데이터 마트를 만들 때, 중간중간에 있는 workflow들을 관리해 준다. 즉, Oozie는 단순히 스케줄러의 작업을 수행하므로 작업을 예약하고 단일 단위로 함께 바인딩한다.
9. YARN(Yet Another Resource Negotiator)
YARN은 Hadoop v1에 있던 Job Tracker의 병목현상을 제거하기 위해 Hadoop v2에 도입이 되었다. 클러스터 전체에서 리소스를 관리하고 하둡 시스템에 대한 스케줄링 및 리소스 할당을 수행함으로 YARN은 빅데이터 처리에 사용되는 대규모 분산 운영체제 라고도 할 수 있다.
YARN은 또한 그래프 처리, 대화 형 처리, 스트림 처리 및 배치 처리와 같은 다양한 데이터 처리 엔진을 통해 HDFS (Hadoop 분산 파일 시스템)에 저장된 데이터를 실행하고 처리 할 수 있기 때문에 시스템을 훨씬 더 효율적으로 만든다. 다양한 구성 요소를 통해 다양한 리소스를 동적으로 할당하고 응용 프로그램 처리를 예약 할 수 있다.
YARN은 크게 아래의 3가지 주요 컴포넌트로 구성되어 있다.
- Resource Manager : 자원을 시스템의 응용프로그램(Application)에 할당이 가능하다.
- Nodes Manager : CPU, 메모리 같은 자원의 할당된 것을 일하고 Resource Manager에 보고한다.
- Application Manager : Resource Manager와 Nodes Manager 간의 인터페이스 역할을 한다.
Application workflow in Hadoop YARN
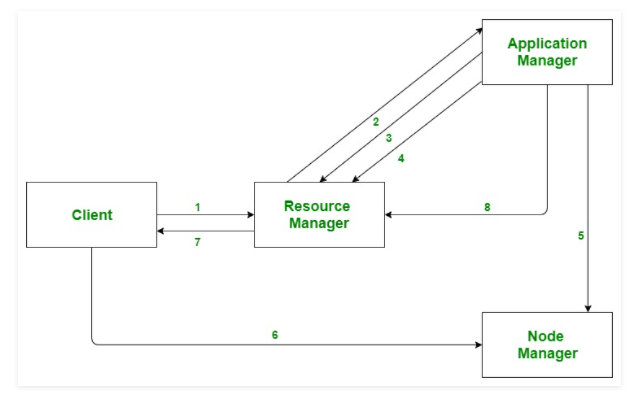
https://www.geeksforgeeks.org/hadoop-yarn-architecture/
- Client submits an application
- The Resource Manager allocates a container to start the Application Manager
- The Application Manager registers itself with the Resource Manager
- The Application Manager negotiates containers from the Resource Manager
- The Application Manager notifies the Node Manager to launch containers
- Application code is executed in the container
- Client contacts Resource Manager/Application Manager to monitor application’s status
- Once the processing is complete, the Application Manager un-registers with the Resource Manager
10. Solr, Lucene
자바 라이브러리의 도움으로 검색 및 인덱싱 작업을 수행하는 두 서비스입니다.
11. Spark
일괄 처리, 반복적 실시간 처리, 그래프 변환 및 시각화 등과 같은 소모적인 프로세스 작업을 처리하는 플랫폼이다. 메모리 리소스를 소비하므로 최적화 측면에서 이전보다 빠르다. Spark는 실시간 데이터에 가장 적합한 반면, Hadoop은 구조화 된 데이터 또는 일괄 처리에 가장 적합하다. 따라서 대부분의 회사에서는 두가지다 변환해가면서 사용되어진다.
출처 : https://han-py.tistory.com/361
하둡(Hadoop) 기초 정리
하둡에 대해 알아보기 전에 큰 흐름에서의 하둡에 대해 이해를 해보자. 하둡은 기본적으로 빅데이터를 처리하는 과정 속에서 사용되어진다. 빅데이터를 처리하는 흐름으로는 우선 데이터를 수
han-py.tistory.com
'DB > 그 외' 카테고리의 다른 글
| [Oracle] SUM()함수에서 NULL값의 처리 (0) | 2023.03.22 |
|---|---|
| [Oracle] 그룹 함수 (ROLLUP, CUBE, GROUPING 등) (0) | 2023.03.21 |
| [Hadoop] 하둡이란? (0) | 2023.02.15 |
| 검색엔진 비교_Solr vs ElasticSearch (0) | 2023.02.09 |
| [데이터베이스] 데이터베이스 설계 (0) | 2023.02.06 |