네이버쇼핑은 네이버가 제공하는 쇼핑 포털 서비스입니다. 네이버쇼핑은 상품을 체계적으로 구성하고 사용자가 보다 쉽게 검색할 수 있도록 상품을 카테고리에 매칭합니다. 하지만 매일 2,000만 개 이상 새로 등록되는 상품을 약 5,000개에 달하는 카테고리에 매칭하는 작업은 사람이 하기에 불가능한 일입니다.
이 글에서는 TensorFlow를 활용해 네이버쇼핑의 상품 카테고리 매칭을 자동화한 과정을 소개하고, 실제 서비스의 데이터에 적용하는 과정에서 나타난 문제점을 해결한 방법을 설명합니다.
네이버쇼핑과 상품 카테고리
네이버쇼핑은 네이버 사용자가 네이버쇼핑에 등록된 업체와 네이버 스마트 스토어의 상품을 쉽게 접할 수 있도록 상품 검색, 카테고리 분류, 가격 비교, 쇼핑 콘텐츠 등을 제공하는 쇼핑 포털 서비스이다.
그림 1 네이버쇼핑 메인 화면
네이버쇼핑에 등록된 상품의 개수는 2005년에 1만 개 미만을 시작으로 2011년에 1억 개를 넘었고 2019년 4월을 기준으로는 15억 개에 달한다. 현재도 하루 평균 2,000만 개의 상품이 새롭게 등록되고 있다.
네이버쇼핑은 이처럼 많은 상품을 체계적으로 구성하고 사용자가 보다 쉽게 검색할 수 있도록 상품을 카테고리로 분류한다. 카테고리는 패션잡화 > 여성신발 > 단화 > 로퍼와 같이 '대분류 > 중분류 > 소분류 > 세분류'로 구별해 관리한다. 현재 네이버쇼핑에서 관리하는 카테고리의 개수는 약 5,000개이다.
카테고리 자동 매칭의 필요성
네이버쇼핑에서 상품을 검색하기 위해 사용자가 키워드를 입력하면 입력된 키워드의 카테고리를 먼저 파악한 뒤 검색 정렬 로직에 따라 키워드 카테고리와 일치하는 상품이 나열된다. 사용자가 원하는 상품을 빠르게 찾고 원하는 검색 결과를 얻을 수 있도록 하려면 상품이 올바른 카테고리에 매칭되어 있어야 한다.
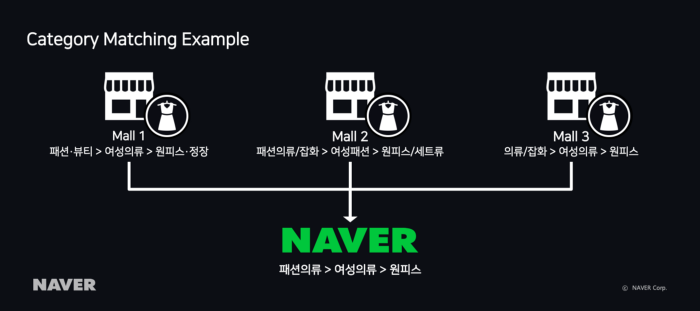
그림 2 카테고리 매칭 예시
네이버쇼핑에 등록된 업체는 네이버쇼핑의 상품 등록을 위한 데이터 형식인 EP(Engine Page) 형식에 맞춰 업체의 카테고리 정보를 포함한 여러 가지 상품 정보를 텍스트 파일로 생성해 네이버쇼핑으로 보낸다.
네이버 쇼핑으로 보낸 다양한 상품 정보에서 카테고리는 업체마다 사용하는 체계가 다르다. 그래서 위의 카테고리 매칭 예시에서처럼 동일한 원피스 일지라도 전부 다른 카테고리 정보를 가지고 있다. 검색 정확도를 높여 쇼핑 검색의 품질을 향상시키려면 업체가 사용하는 카테고리를 네이버쇼핑에 맞는 카테고리로 매칭하는 작업이 필수로 이루어져야 한다.
문제는 매일 2,000만 개 이상의 신규 상품이 등록되고 그 규모가 점점 커지는 상황에서 새로운 상품을 일일이 약 5,000개의 네이버쇼핑의 카테고리에 적절하게 매칭하는 일을 사람이 할 수는 없다는 점이다. ‘업체의 데스크탑용 HDD 카테고리는 네이버쇼핑의 HDD 카테고리로 매핑한다'와 같이 규칙을 기반으로 한 카테고리 매칭 방법도 사용했지만 업체와 상품의 수가 증가하고 네이버쇼핑의 카테고리가 빈번하게 개편되면서 규칙 기반의 카테고리 매칭은 더 이상 사용할 수 없게 되었다.
하지만 카테고리 매칭을 전형적인 딥러닝의 분류(classification) 문제로 보고 NLP(natural language processing)와 컴퓨터 비전(computer vision)과 같은 기술을 적용하면 카테고리 매칭을 자동화할 수 있다.
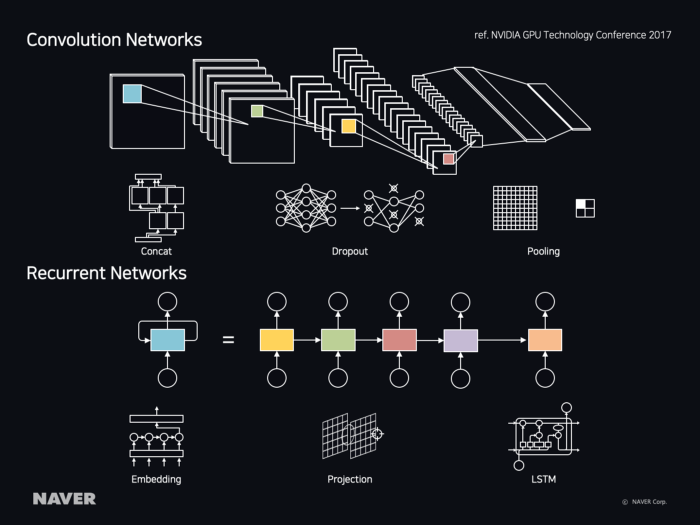
그림 3 NLP와 computer vision을 위한 CNN 아키텍처와 RNN 아키텍처
네이버쇼핑에 NLP를 적용할 때에는 고려할 사항이 있다. 일반적인 자연어 처리에서는 상품의 속성(예: 300ml, 500GB), 모델 코드(예: SL-M2029, PIXMA-MX922)와 같은 단어는 stop word로 처리되어 무시된다. 하지만 쇼핑에서는 중요하게 사용되는 단어이다. 쇼핑 도메인을 위한 자연어 처리 방법(자연어 처리를 위한 쇼핑용 사전 등)을 개발해야 한다.
카테고리 자동 매칭 시스템 아키텍처
현재 네이버쇼핑은 카테고리 자동 매칭을 위한 시스템에서 학습과 분류를 위해 다음과 같은 아키텍처를 사용하고 있다.

그림 4 카테고리 자동 매칭 시스템 아키텍처
데이터베이스(Relational Database)에 존재하는 약 15억 건의 상품 정보는 검색 결과(Search Result Sets)로 사용자에게 제공된다. 모니터링 센터(Monitoring Center)는 검색 결과 중에서 카테고리가 잘못 매칭되어 있는 상품을 찾아 올바른 카테고리로 매칭한다.
모니터링 센터에서 매칭한 상품은 사람이 직접 확인한 데이터이기 때문에 정제된 데이터로 보고 분산 데이터베이스(Distributed Database)에서 학습 데이터로 추출한다. 정제된 데이터 이외에도 상품의 다양한 특성을 고려해 학습 데이터가 추출된다.
학습 서버(Training Server 1, Training Server 2)는 분산 데이터베이스에 있는 데이터를 읽어와 모델을 학습시키고, 이렇게 개선된 모델은 분류 서버(Inference Server)로 배포된다. 분류 서버는 매일 약 2,000만 건의 신규 상품(네이버의 카테고리에 매칭되지 않은 상품) 정보를 데이터베이스에서 읽어와 카테고리를 매칭한 다음 데이터베이스에 업데이트한다.
카테고리 자동 매칭 모델
네이버쇼핑의 카테고리 자동 매칭 모델은 다음과 같은 과정으로 상품이 가지고 있는 데이터의 특성을 분석하고 그 특성에 맞는 모델을 활용한다.
- Find Product’s feature: 상품 정보에서 유용한 feature를 찾는다.
- Morphology Analysis: 상품 정보에서 term을 분석하고 추출한다.
- Word Embedding: 상품의 feature를 vector로 변환한다.
- CNN-LSTM Model — Product Name: 상품명에 CNN-LSTM 모델을 적용한다.
- MobileNetV2 — Product Image: 상품 이미지에 MobileNetV2 모델을 적용한다.
- Multi Input Model — Product Misc. Information: 상품이 가지고 있는 다양한 데이터를 입력으로 모델을 연결해 정확도를 높인다.
1. Find Product’s feature
다음 그림에서 표시한 요소는 카테고리 자동 매칭에서 유용하게 사용될 feature이다.

그림 5 카테고리 자동 매칭에 사용된 상품의 feature
위의 예에서 상품명만으로는 여성 티셔츠인지, 강아지 티셔츠인지 구별할 수 없다. 하지만 이미지를 보면 쉽게 구별이 가능한 것처럼 ‘상품명(Product Name)’과 ‘이미지(Image)’는 사용자가 상품을 구입하기 위해 가장 우선으로 살펴보는 요소이다. 검색 결과에서 카테고리가 잘못 매칭된 상품이 발견될 때 모니터링 센터가 상품을 올바른 카테고리로 이동(데이터를 정제)하기 위해서도 상품명과 이미지를 중요하게 살펴봐야 한다.
따라서 카테고리 자동 매칭에서도 상품명과 이미지를 주요 feature로 사용했다. 상품명과 이미지뿐만 아니라 업체에서 제공하는 수십 가지의 상품 정보에서 업체에서 사용하는 카테고리(네이버쇼핑 카테고리 체계와는 다른 카테고리), 상품의 최저가(Lowest Price), 브랜드(Brand), 메이커(Maker), 원본 이미지 비율(Original Image Ratio) 또한 추가 feature로 활용했다.
2. Morphology Analysis
주요 feature로 사용될 상품명에는 다음과 같은 특징이 있다.
- 상품명에 주로 명사가 사용된다.
- 한국어와 영어가 혼용된 상품명이 있다.
- 영문자와 숫자로 조합된 모델 코드가 포함된 상품명이 있다.
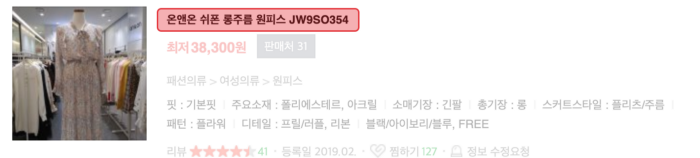
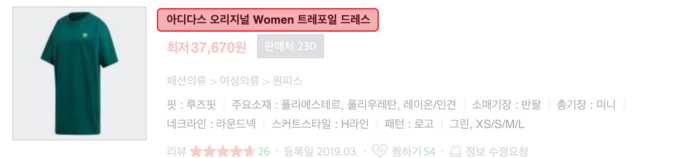
- 상품의 콘셉트를 설명하는 단어(예: 루즈핏)가 포함된 상품명이 있다.

- 띄어쓰기가 없는 상품명이 있다. 한글의 특성상 띄어쓰기가 없어도 의미 해석이 가능하다.

상품명에 있는 단어가 쇼핑 도메인에 맞는 의미를 가지려면 띄어쓰기가 없는 상품명은 term 단위로 추출되면서도 콘셉트를 설명하는 단어나 모델 코드, 상품 속성 등은 분리되지 않아야 한다.
다음은 네이버의 사내 언어 처리 시스템을 사용해 형태소를 분석한 뒤 상품명에서 term을 추출한 예이다. term을 추출하기 전에 정규표현식으로 상품명에서 특수 문자를 제거했다(단, 모델 코드에서 자주 사용되는 줄표(-)는 제거하지 않는다).
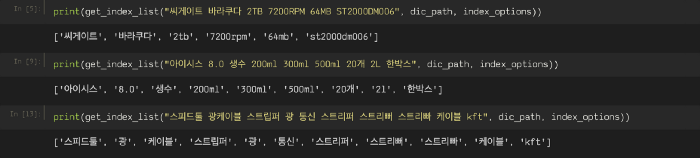
그림 6 상품명 term 추출 결과 예시
3. Word Embedding
상품명은 쇼핑이라는 도메인에 특화되어 있기 때문에 많은 정보를 잃지 않고 상품을 효과적으로 모델의 입력으로 넣을 수 있는 방법을 고민했다. 단어 사전을 만든 뒤 숫자를 부여하는 random sequence 방식(예: 여아용=1000, 남아용=1001)은 모델에서 비슷하게 활성화되어 단어의 의미와 관계를 잃기 쉬우므로 단어를 고차원에 매핑하여 vector로 표현하는 방식을 사용했다.
Wikipedia의 내용으로 사전 학습이 이루어진(pre-trained) vector를 사용하려고 했으나 word embedding이 구축될 때 상품 데이터의 특징이 고려되지 않았을 것이라고 생각했다. 그래서 직접 Word2vec 방법을 사용해 상품 데이터의 특징이 포함된 word embedding을 구축했다.
4. CNN-LSTM Model — Product Name
텍스트 데이터인 상품명에는 다음과 같은 순서로 CNN-LSTM 모델을 적용해 학습한다.
- CNN 모델: 상품명에서 텍스트 특정 지역의 feature를 추출한다.
- LSTM 모델: 길이가 긴 상품명에서 주변 단어를 기반으로 현재 단어의 의미를 파악한다.
- CNN-LSTM 모델: CNN으로 추출한 지역적인 feature를 LSTM에서 순차적으로 통합해 사용한다.
1. CNN 모델
CNN(Convolution Neural Network) 모델은 원래 이미지 처리를 위해 처음 만들어진 네트워크이다. 이 모델은 이미지 속 물체의 위치와는 상관없이 필터가 움직이면서 이미지의 feature를 추출한다.

그림 7 CNN(Convolution Neural Networks)
이미지뿐만 아니라 NLP에서도 CNN 알고리즘을 적용하려는 많은 노력이 있었다. “Convolutional Neural Networks for Sentence Classification” 논문에 따르면 이미지 처리에서 CNN 필터는 이미지 특정 지역의 feature를 추출할 수 있고, 텍스트 처리에서는 텍스트 특정 지역의 feature를 추출할 수 있다.
네이버쇼핑의 상품명에서는 다음과 같이 위치와 무관하게 나타나는 상품의 주요 키워드를 볼 수 있다.
- 아디다스 오리지널 Women 트레포일 드레스
- 온앤온 쉬폰 롱주름 원피스 JW9SO354
2. LSTM 모델
LSTM(Long-Term Short Term Memory) 모델은 RNN(Recurrent Neural Networks) 기반의 네트워크이다.

그림 8 LSTM(Long Short-Term Memory)
RNN은 현재 입력 데이터에서 이전의 입력 데이터를 기억해 이전 단계에서 얻은 정보가 지속되도록 하는 네트워크이다. 하지만 RNN은 긴 기간 의존성(long-term dependencies) 문제(예를 들어 짧은 문장에서는 단어를 잘 예측하나 긴 문장에서는 단어를 잘 예측하지 못한다)를 해결하지 못했다. 이 문제를 해결한 것이 LSTM 모델이다.
일반적으로 글에서 나타나는 단어의 의미(예를 들어 반어법)는 주변 단어들(앞 단어, 뒷 단어)을 기반으로 파악한다. 그렇기 때문에 LSTM 모델은 글과 같이 순차적으로 등장하는 데이터 처리에 적합한 모델로 알려져 있다.
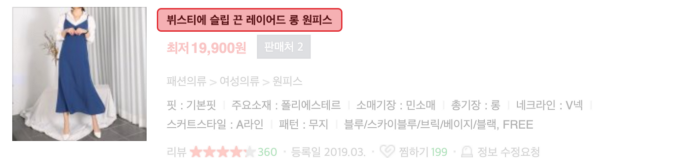
네이버쇼핑의 상품명에서는 다음과 같이 주변의 키워드를 함께 보아야 분류가 가능한 상품명을 볼 수 있다.
- 뷔스티에 슬립 끈 레이어드 롱 원피스
- 셔츠 루즈핏 카라 롱 원피스
3. CNN-LSTM 모델
다음은 “Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model” 논문에서 제안한 CNN-LSTM 모델의 아키텍처이다.

그림 9 CNN-LSTM Model
CNN-LSTM 모델은 일반적인 NN(Neural Network) 모델보다 훨씬 더 뛰어난 성능을 보인다. word embedding(vector)을 입력으로 convolution layer와 max pooling layer를 통과해 지역적인 특징을 추출한 다음 LSTM 모델을 사용해 feature를 연속으로 통합하는 방식이다.
CNN 모델은 입력된 텍스트를 여러 영역으로 나누어 특정 지역의 정보를 추출할 수는 있지만 긴 문장에서는 단어 간의 의존성을 파악하지 못한다. CNN 모델과 LSTM 모델을 결합해 문장 내의 지역 정보를 순차적으로 통합하면 이러한 한계를 해결할 수 있다.
5. MobileNetV2 — Product Image
MobileNet은 상대적으로 적은 리소스로 이미지 분류(image classification), 개체 탐지(object detection)가 가능한 모델이다.
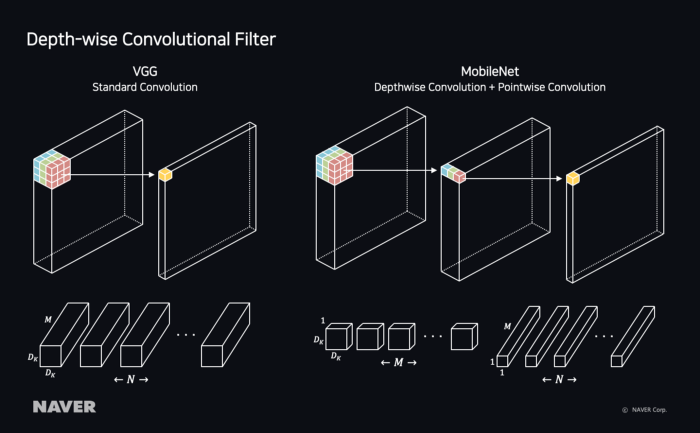
그림 10 MobileNet — Depth wise Convolutional Filter
MobileNet이 나오기 전 모델인 VGG는 여러 가지의 레이어로 구성된 Deep Neural Nets이다. ILSVRC(Large Scale Visual Recognition Challenge)에서 2위를 차지할 만큼 성능이 좋지만 파라미터가 많아 용량 및 리소스가 제한된 컴퓨터(예를 들어 모바일)에서는 사용하기 어려운 모델이다.
성능과 효율성 사이의 균형을 맞추려는 연구가 이어지며 2017년 4월에 Google은 Standard Convolution을 분해해 Depth-wise Convolutional Filter를 사용하는 MobileNets를 발표했다. 그 후 1년 만인 2018년 4월에는 Linear Bottlenecks 구조와 Residual Connection을 사용한 MobileNetV2를 발표했다.
VGG와 비교했을 때 MobileNet의 정확도는 비슷하다. 하지만 MobileNet은 VGG에 비해 연산량과 파라미터의 개수가 1/10 수준이라 GPU 장비가 없는 서버나 실시간성이 필요한 서비스에 적합하다.
6. Multi Input Model — Product Misc. Information
카테고리 자동 매칭을 위해서는 상품명을 사용한 모델과 이미지를 사용한 모델을 별개로 만들어 학습시킬 수 있다. 하지만 상품명과 이미지는 하나의 상품에 관련된 데이터이기 때문에 같이 학습하면 모델의 정확도가 향상된다.
상품명과 이미지뿐만 아니라 다음 그림과 같이 상품이 부가적으로 가지고 있는 브랜드, 메이커, 원본 이미지 비율, 업체에서 사용하는 카테고리, 상품의 최저가까지 함께 학습하면 상품에 관련된 속성의 관계를 학습할 수 있다.
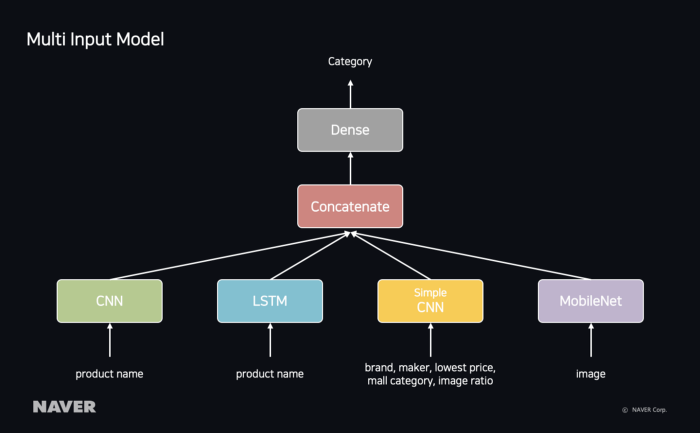
그림 11 Multi Input Model
카테고리 자동 매칭에서 발견된 문제와 해결 방법
실제 서비스 데이터에 카테고리 자동 매칭 모델을 적용할 때 몇 가지 문제점이 발견되었다.
Feature Visualization
카테고리 자동 매칭 모델을 적용하기 전에 카테고리 매칭 결과가 올바른 분포를 가지고 있는지 확인할 수 있는 방법이 있어야 한다. TensorFlow의 Embedding Projector에 데이터에 맞는 feature vector와 label을 업로드하면 카테고리 분포와 카테고리 간의 거리를 눈으로 쉽게 확인할 수 있다. 다음은 약 4,000개의 카테고리 vector를 시각화한 결과이다.

그림 12 Feature Visualization
하나의 점(카테고리)을 클릭하면 그 점과 가까이에 잇는 점(비슷한 카테고리)이 무엇인지 볼 수 있다. 만약 시각화 결과에서 가까운 위치에 있는 점이지만 실제로는 전혀 관련이 없는 카테고리라면 매칭이 잘못될 가능성이 높은 카테고리임을 의미한다.
카테고리 vector 시각화를 위한 feature vector와 label은 다음 예와 같은 코드를 사용해 추출했다.
import numpy as np
import pandas as pd
from keras.models import Model# Get Unique y_label, index
y_valid_uniq, y_valid_uniq_idx = np.unique(y_valid, return_index=True)# Load Model
# ...# Get Feature Vector
fetr_layer_model = Model(inputs=model.input, outputs=model.get_layer('prod_nm_fetr').output)
fetr_output = fetr_layer_model.predict([x_valid])feat_vis = []
label_vis = []
for i in range(len(y_valid_uniq_idx)):
feat_vis.append(fetr_output[y_valid_uniq_idx[i]].tolist())
label_vis.append(label_names[y_valid[y_valid_uniq_idx[i]]]) # sequence to label name# Save to File
feat_vis_df = pd.DataFrame(feat_vis)
label_vis_df = pd.DataFrame(label_vis)feat_vis_df.to_csv('feat_vis.tsv', '\t', header=False, index=False)
label_vis_df.to_csv('label_vis.tsv', '\t', header=False, index=False)Data Normalization
네이버쇼핑에서 인기 있는 카테고리인 ‘패션의류 > 여성의류 > 원피스’와 비인기 카테고리인 ‘생활/건강 > DVD > 교양/다큐멘터리’의 상품 수 비율은 약 1000:1 정도로 데이터가 매우 불균형하다. 이처럼 카테고리별 상품의 분포가 불균형한 학습 데이터로 학습시키면 모델은 전체적인 정확도를 높이기 위해 상품 수가 더 많은 카테고리로 정답이 편향(bias)되는 문제가 발생한다.
아래의 왼쪽 그래프는 data normalization을 적용하기 전으로, 카테고리별 상품 분포도가 지수함수 형태를 나타낸다. 따라서 data normalization을 위해 학습 데이터에 다음과 같은 log 함수를 적용했다.


정규화된 상품 수

상품 개수 조절 상수

카테고리별 상품 수
data normalization을 적용하면 오른쪽 그래프와 같이 카테고리별 상품 수가 고르게 분포되고 정답이 인기 카테고리로 치우치는 문제를 해결할 수 있었다.
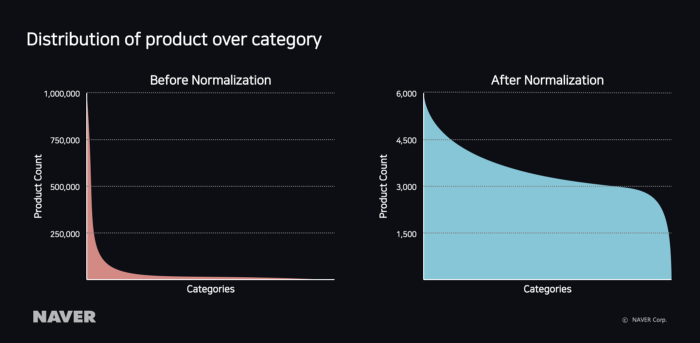
그림 13 카테고리별 상품 분포도
Reflecting trends
온라인 쇼핑몰의 상품은 수명이 짧고 유행에 매우 민감하다. 특히 패션 의류와 같은 카테고리의 상품은 계절별로 생산되기 때문에 상품이 삭제되었다 생성되었다를 반복하는 현상을 볼 수 있다. 예를 들어 텍스트로만 학습된 모델은 ‘아노락’과 같은 새로운 유행 상품이 유입되었을 때 단어만 보고 어떤 카테고리인지 파악하기 어렵다. 텍스트와 이미지를 같이 학습시킨 모델은 ‘아노락’이라는 새로운 상품이 유입되어도 이미지를 활용해 재킷으로 분류할 수 있다.
이러한 경우에 다음 그래프와 같이 Long-Term Accuracy를 분석해 모델이 앞으로도 정확하게 예측할 수 있는지 확인하고 학습 데이터와 모델 또한 그에 맞춰 지속적으로 업데이트하면서 상품의 유행을 따라갈 수 있어야 한다.
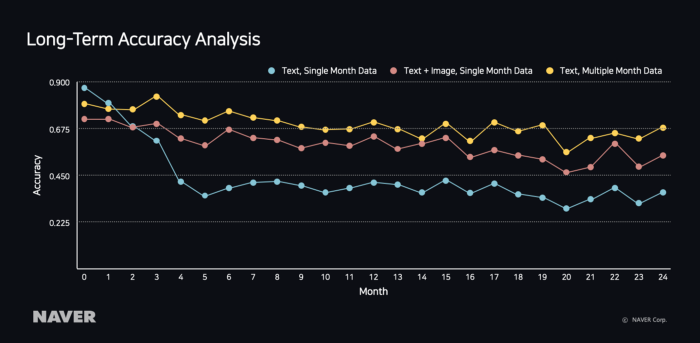
그림 14 Long-Term Accuracy 분석
Training Data Pipeline
보통 학습 데이터를 업데이트하기 위해서는 HDFS에 SQL 구문을 통해 추출하고 다시 학습 서버에 파일로 저장한 뒤 코드 내에서 데이터를 로딩해 모델을 재학습시켜야 한다. 이런 일반적인 방법은 학습 데이터가 클수록 파일로 저장하고 로딩하는 시간이 길어질 뿐만 아니라 서버의 디스크 공간도 많이 차지하므로 비효율적이다.

그림 15 데이터 파이프라인 성능 비교
TensorFlow에서는 tf.data 파이프라인을 사용해 HDFS에 있는 학습 데이터를 직접 읽어오는 방법을 제공한다. 다음 예와 같이 Dataset.prefetch() 메서드를 사용하면 학습 데이터를 나눠서 읽어오기 때문에 첫 번째 데이터를 GPU에서 학습하는 동안 두 번째 데이터를 CPU에서 준비할 수 있어 리소스의 유휴 상태를 줄일 수 있다.
import tensorflow as tf# tf.data Generator
def data_generator(locations, batch_num, epoch_num, labels):
dataset = tf.data.TextLineDataset(locations)
dataset = dataset.repeat(epoch_num)
dataset = dataset.prefetch(buffer_size=batch_num)
dataset = dataset.batch(batch_num)
iterator = dataset.make_one_shot_iterator()
next_batch = iterator.get_next() sess = tf.Session()
while True:
try:
batch = sess.run(next_batch)
# Do Transform Some Data
y = np.array([labels[record[0]] for record in batch])
x_prod_nm = np.array([record[1] for record in batch])
x_image_feat = np.array([np.array(record[5].split(','), dtype=float) for record in batch])
yield ({'prod_nm': x_prod_nm, 'image_feat': x_image_feat}, {'output': y})
except tf.errors.OutOfRangeError:
break# Training data Generator
train_locations = ['hdfs://hadoop_server_address:8020' + filepath for filepath in train_filepaths]
train_generator = data_generator(train_locations, batch_size, epoch_size, label_dict)# Build Model
# ...# Training Model using Keras fit_generator
hist = model.fit_generator(generator=train_generator, epochs=epoch_size, verbose=1)남아 있는 작업
실제 데이터에서 발생한 문제점을 해결하며 카테고리 자동 매칭 모델을 개선하기 위해 노력했지만 아직 개선해야 할 사항들이 남아있다.
분류가 모호한 카테고리
네이버쇼핑의 카테고리는 사용자 편의를 위한 카테고리 구조로, 동일한 이름의 하위 카테고리가 다수 존재해 상위 카테고리를 구별하기 어렵다. 모델이 학습하기에는 좋지 않은 구조이기 때문에 별도의 학습이 필요한 카테고리를 선별해 모델이 학습하기 쉬운 구조로 변경하거나, 커머스 환경에 존재하는 표준 카테고리(예: UNSPSC(The Unitited Nations Standard Products & Services Code)) 군을 별도로 관리해 학습하는 방식이 필요하다.

그림 16 분류가 모호한 카테고리
업체에서 유입되는 오류 정보
업체에서 상품 정보를 보낼 때 판매자가 직접 상품의 카테고리를 네이버쇼핑 카테고리에 매칭해서 보내는 경우가 있다. 이 정보도 사람이 직접 카테고리를 매칭한 데이터이므로 학습 데이터로 사용하는 조건 중 하나이다. 하지만 학습에 사용되는 대표적인 상품 요소에 오류가 내포된 경우도 있다. 학습 데이터에서 오류 데이터를 제거하기 위해서는 품질 높은 상품 정보를 보내는 업체를 선정해 학습에 가중치를 부여하는 방법 등을 사용해야 한다.
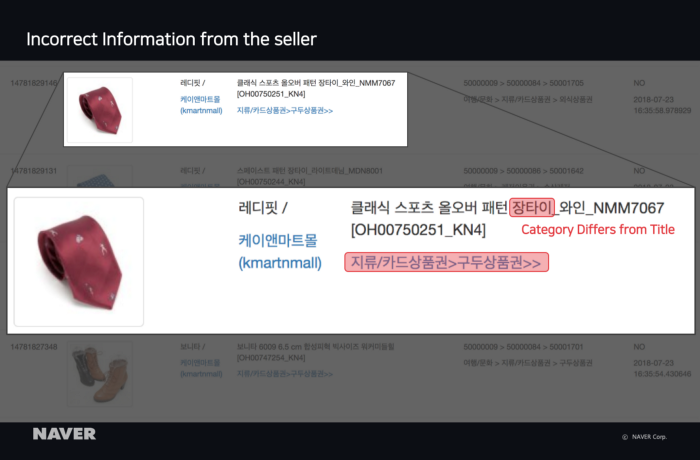
그림 17 업체에서 유입되는 오류 정보 예시
마치며
지금까지 네이버쇼핑에서 운영되고 있는 카테고리 자동 매칭 모델을 설명하고 관련된 문제점 및 해결 방법을 살펴봤다.
먼저 상품에서 유용한 feature를 찾고 텍스트 데이터의 경우에는 형태소를 분석한 뒤 CNN과 LSTM 모델을 활용했다. 이미지 데이터의 경우에는 MobileNet 모델을 활용해 카테고리 자동 매칭 모델을 개발했다.
이외에 TensorBoard를 사용한 데이터 시각화와 data normalization, TensorFlow의 파이프라인을 사용하는 방법도 살펴보았다.
이 프로젝트를 진행하면서 실제 서비스 환경에서 모델을 적용했을 때 모델의 정확도만 보는 것이 아니라 그 이외의 문제점이 무엇인지 파악하는 과정에서 머신러닝, 딥러닝의 문제점을 더욱 깊게 이해할 수 있었다.
현재 카테고리 자동 매칭의 정확도는 약 85%이다. 상품명 데이터 정제, 이미지 feature 추출 효율화, 정확한 검증 세트 구축 등의 다양한 방법을 활용해 모델이 더욱 높은 정확도를 가질 수 있도록 개선해 나가고자 한다.
TensorFlow를 활용한 네이버쇼핑의 상품 카테고리 자동 분류
네이버쇼핑은 네이버가 제공하는 쇼핑 포털 서비스입니다. 네이버쇼핑은 상품을 체계적으로 구성하고 사용자가 보다 쉽게 검색할 수 있도록 상품을 카테고리에 매칭합니다. 하지만 매일 2,000만
medium.com
'그 외 개발관련 > etc.' 카테고리의 다른 글
| [챗봇] 그래서 스킬 데이터를 어떻게 주고받는데? ( 카카오 챗봇 ) (3) | 2023.03.21 |
|---|---|
| [챗봇] 카카오톡 챗봇을 위한 카카오 i 오픈 빌더 이해하기 (0) | 2023.02.10 |
| TCP/IP 응용(애플리케이션) 계층과 URL 구성 요소 및 종류 (0) | 2023.02.10 |